MEMO: A Modular Framework for Training a Dedicated Memory Model on New Knowledge Without Modifying LLM Parameters
MarkTechPost
Read Full Article at MarkTechPost →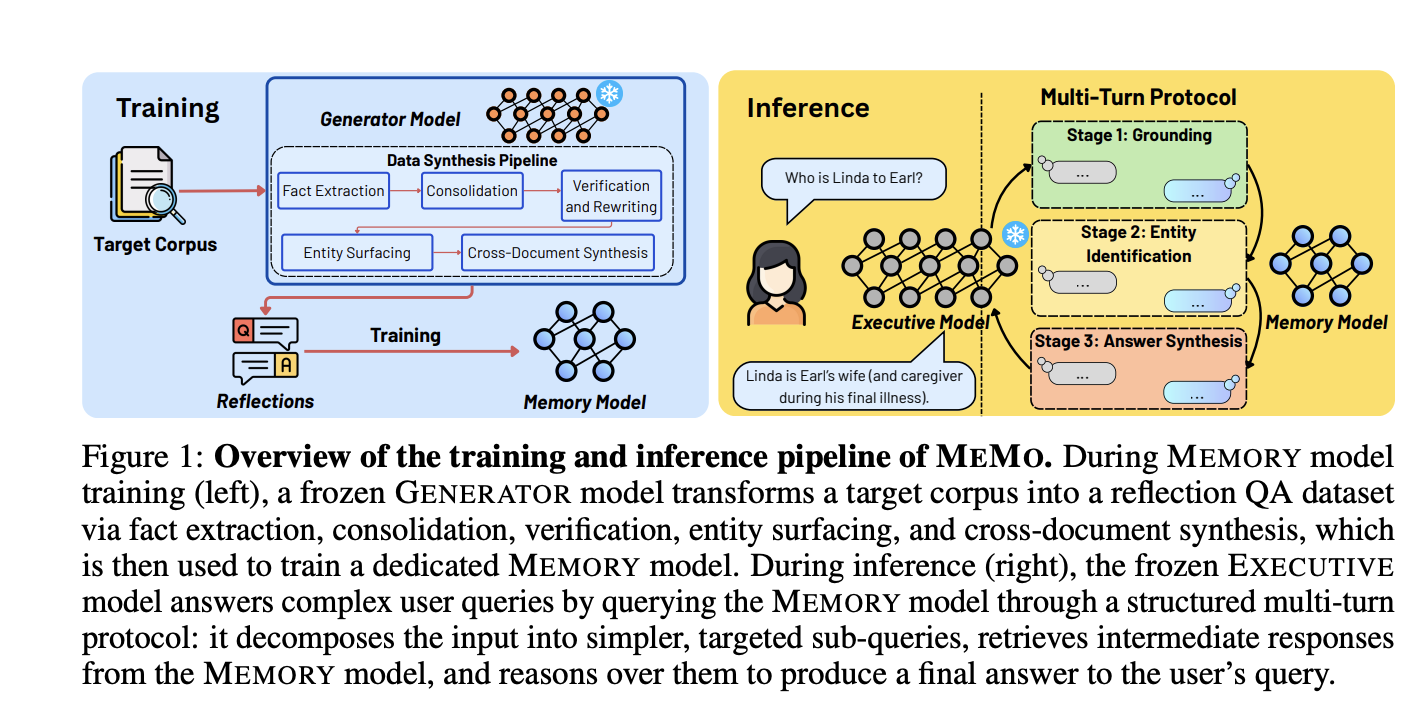
Ad Slot — In-Article (728x90)
Researchers from NUS, MIT, and A*STAR propose MEMO, a modular framework that encodes corpus knowledge into a separate trainable MEMORY model. The post MEMO: A Modular Framework for Training a Dedicated Memory Model on New Knowledge Without Modifying LLM Parameters appeared first on MarkTechPost.
This is a summary. For the full story, read the original article at MarkTechPost.
Original source: MarkTechPost