MiniMax Sparse Attention (MSA): a Two-Branch Block-Sparse Attention Trained on a 109B-Parameter MoE With a 3T-Token Budget
MarkTechPost
Read Full Article at MarkTechPost →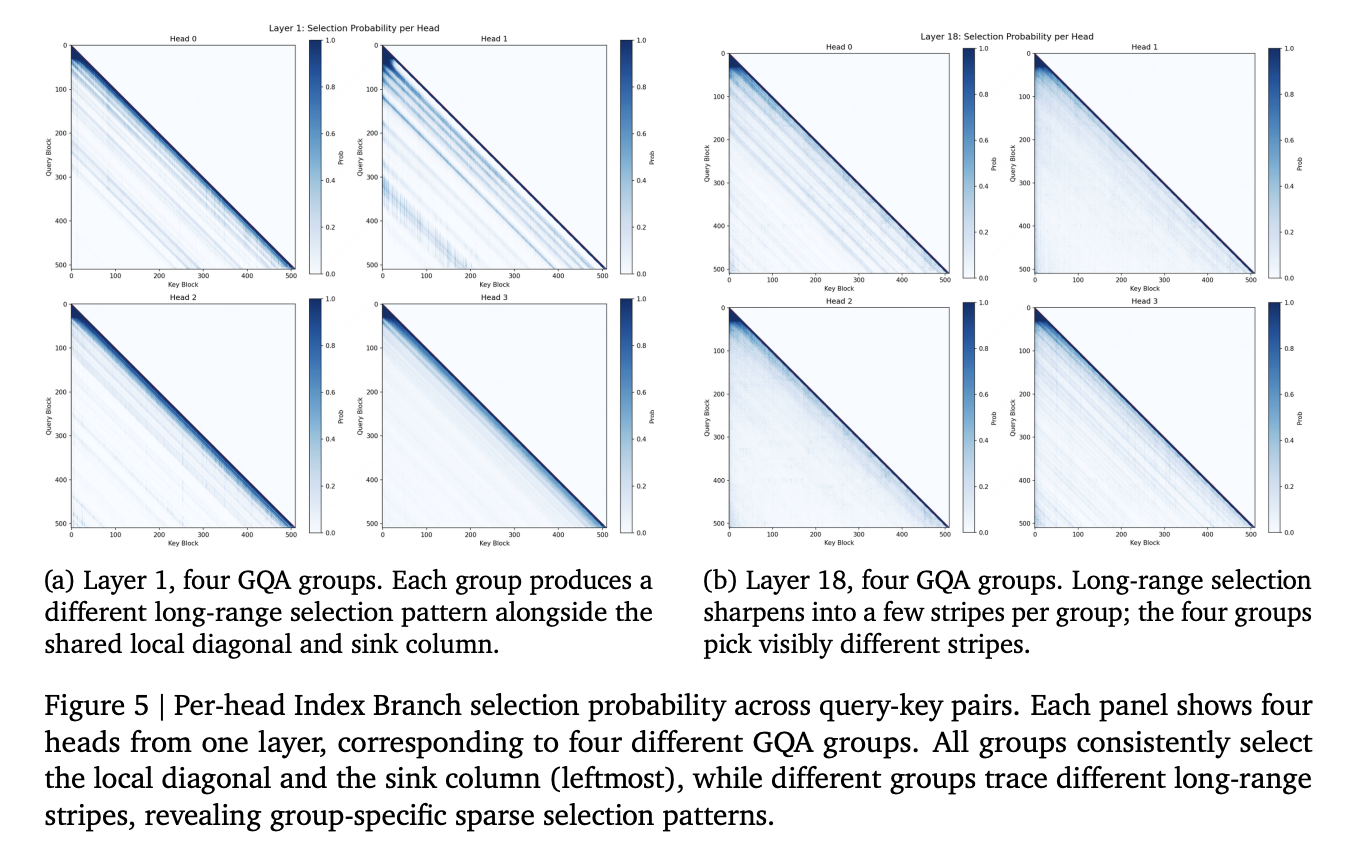
Ad Slot — In-Article (728x90)
MiniMax released MSA, a sparse attention built on Grouped Query Attention. A lightweight Index Branch selects Top-k key-value blocks per query and GQA group; the Main Branch attends only to those blocks. It matches GQA on downstream benchmarks while reducing per-token attention compute 28.
4× at 1M context. The post MiniMax Sparse Attention (MSA): a Two-Branch Block-Sparse Attention Trained on a 109B-Parameter MoE With a 3T-Token Budget appeared first on MarkTechPost.
This is a summary. For the full story, read the original article at MarkTechPost.
Original source: MarkTechPost