OpenMOSS Releases MOSS-Audio: An Open-Source Foundation Model for Speech, Sound, Music, and Time-Aware Audio Reasoning
MarkTechPost
Read Full Article at MarkTechPost →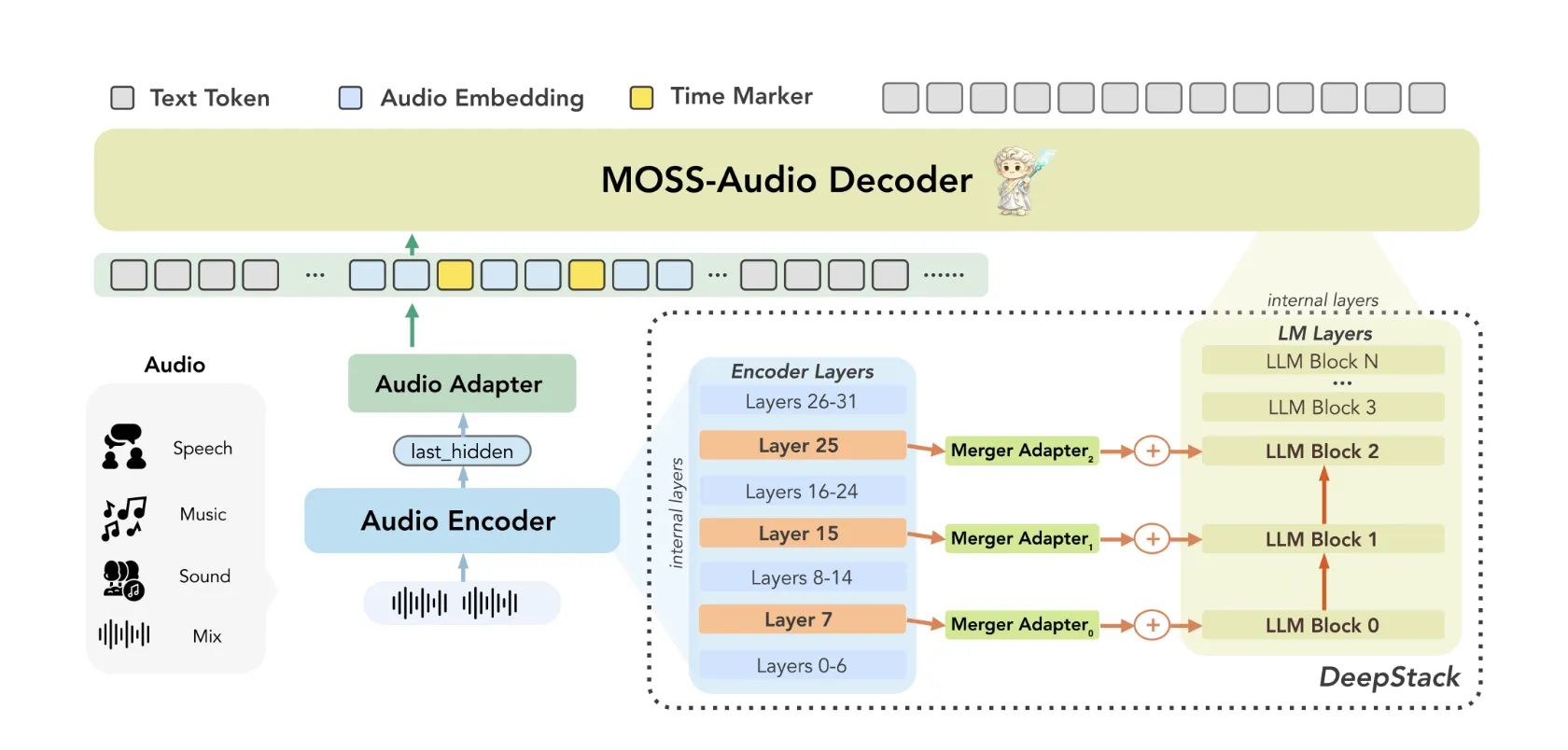
Ad Slot — In-Article (728x90)
The model unifies speech, environmental sound, music, and temporal reasoning into a single architecture — and outperforms every open-source model tested on general audio benchmarks, including systems more than four times its size.
The post OpenMOSS Releases MOSS-Audio: An Open-Source Foundation Model for Speech, Sound, Music, and Time-Aware Audio Reasoning appeared first on MarkTechPost.
This is a summary. For the full story, read the original article at MarkTechPost.
Original source: MarkTechPost