Together AI Open-Sources OSCAR: An Attention-Aware 2-Bit KV Cache Quantization System for Long-Context LLM Serving
MarkTechPost
Read Full Article at MarkTechPost →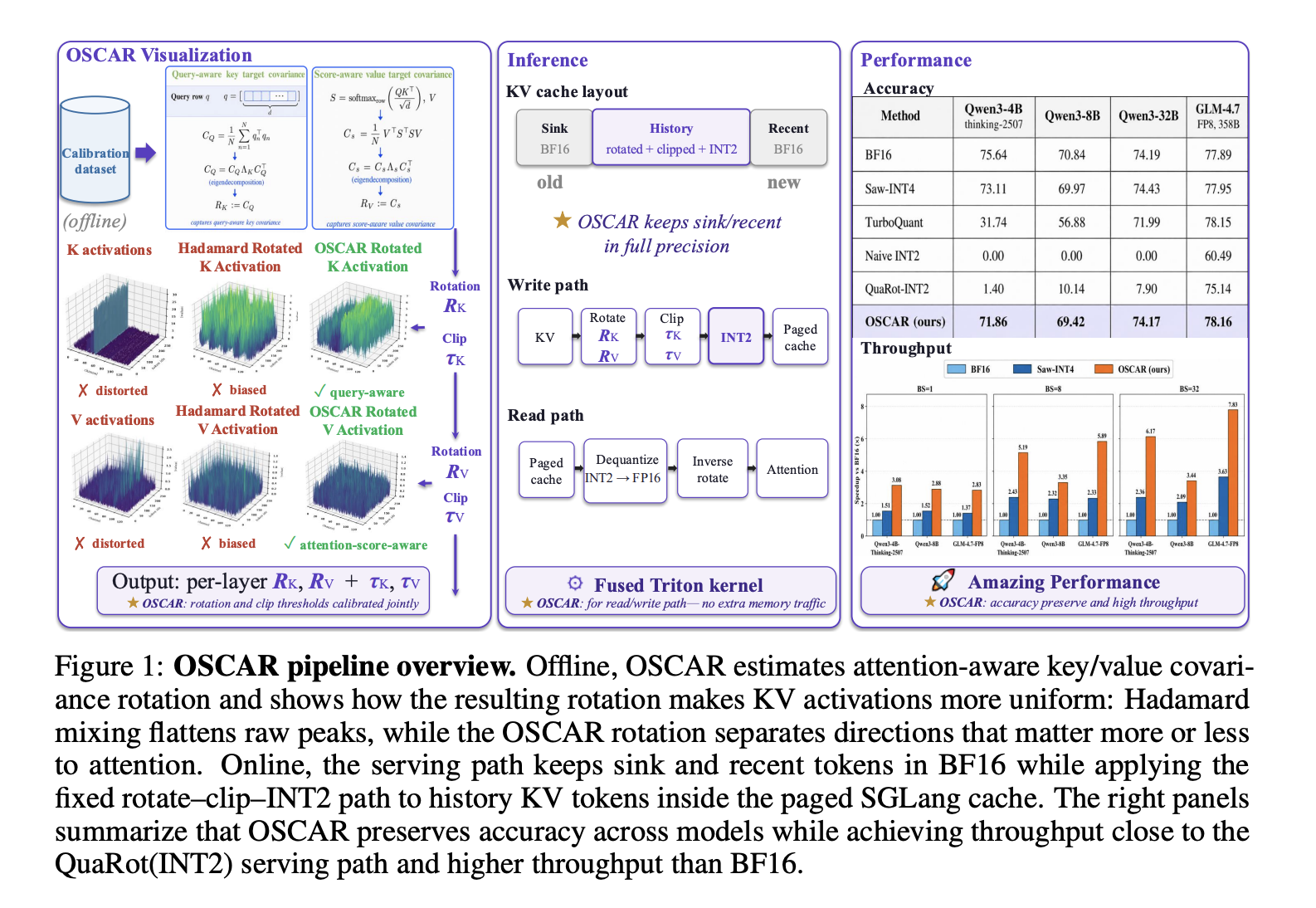
Ad Slot — In-Article (728x90)
Together AI has released OSCAR (Offline Spectral Covariance-Aware Rotation), an INT2 KV cache quantization method for long-context LLM serving.
Unlike prior rotation-based approaches that apply data-oblivious Hadamard transforms, OSCAR derives separate rotations for keys and values from attention-aware covariance structures estimated offline. At 2. 28 bits per KV element, OSCAR reduces the BF16 accuracy gap to 3.
This is a summary. For the full story, read the original article at MarkTechPost.
Original source: MarkTechPost